
About meA few interesting things about me. I love to read science fiction (my favorite is Frank Herbert's Dune). I am also an avid gamer. I love to play competitive strategy games and first-person shooters. Lastly, I love learning. Every day I push myself to learn something new, whether that be about machine learning, software engineering, or miscellaneous facts about the universe.
On top of recently getting married and graduating with a masters in computer science from UT Dallas, I also recently started working as a senior data scientist at Capital One. My work mainly revolves around utilizing natural language processing to build a more intelligent customer experience.
I utilize AWS to develop and productionize machine learning systems.
I apply text analytics to some of the hardest questions in business.
I am passionate about learning the theory that is pushing the cutting edge of ML.
HIVE, Hadoop, and Spark, Oh my!
I enjoy working with my team to create winning strategies.
I love telling a story. Getting to the heart of a problem and coming up with a solution.
Take a look at my recent work.

A helpful tutorial I wrote recently on how to set up a Bash script that utilized the AWS CLI to start, log into, then shutdown an EC2 instance. (I didn't want to forget the instance was running and lose money)
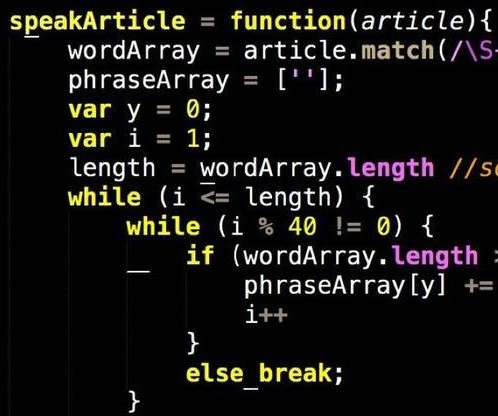
Tested the use of Word2Vec embeddings with a variety of sequential input deep learning models towards the task of language modeling (predicting the next word in a sentence).

A fully functional, SQL-compliant database implemented from scratch in Python. DavisBase compresses data to a custom-designed bit-level encoding for maximal data compression. By utilizing a file size of 512Kb, DavisBase performs well in low memory environments while also maximizing query time.

